




本次和大家聊一下TCP性能优化。
TCP全称为Transmission Control Protocol,每一个IT人士对TCP都有一定了解。TCP协议属于底层协议,对于大部分研发人员来说,这是透明的,无需关心TCP的实现与细节。
不过如果想做深入的性能优化,TCP是绕不过去的一环。要讲TCP性能优化,必须先回顾一下TCP的一些细节。让我们先来看一下TCP的首部格式
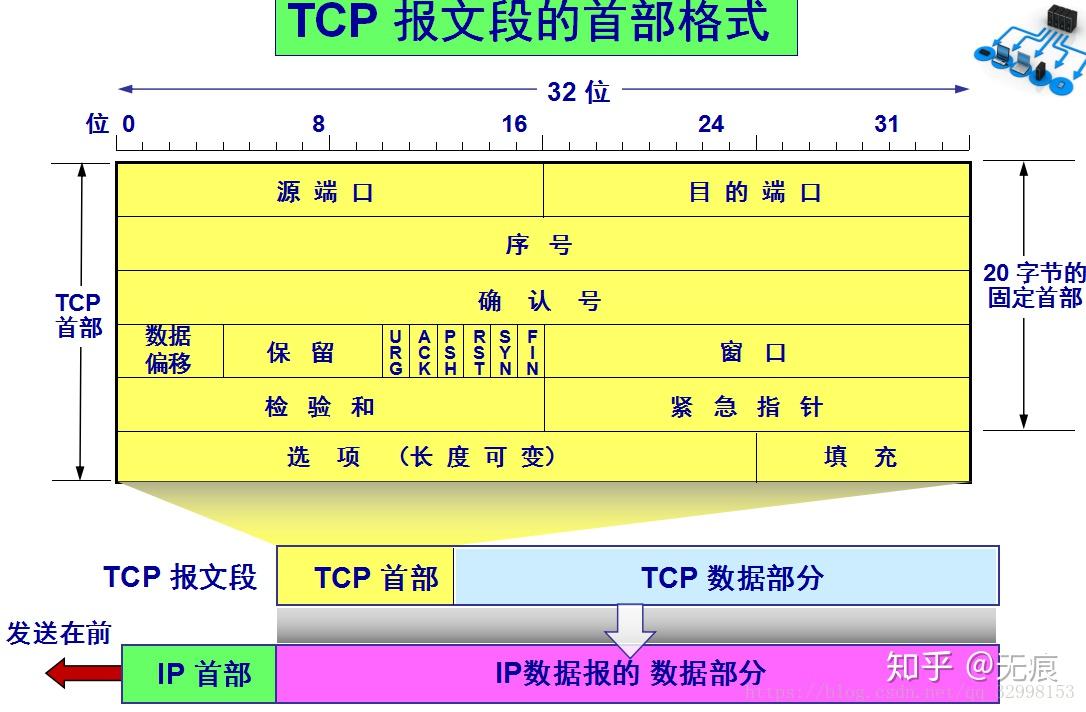
TCP报文段首部的前20个字节是固定的,后面有4n字节是根据需要而增加的选项(n是整数)。因此TCP首部的最小长度是20字节。

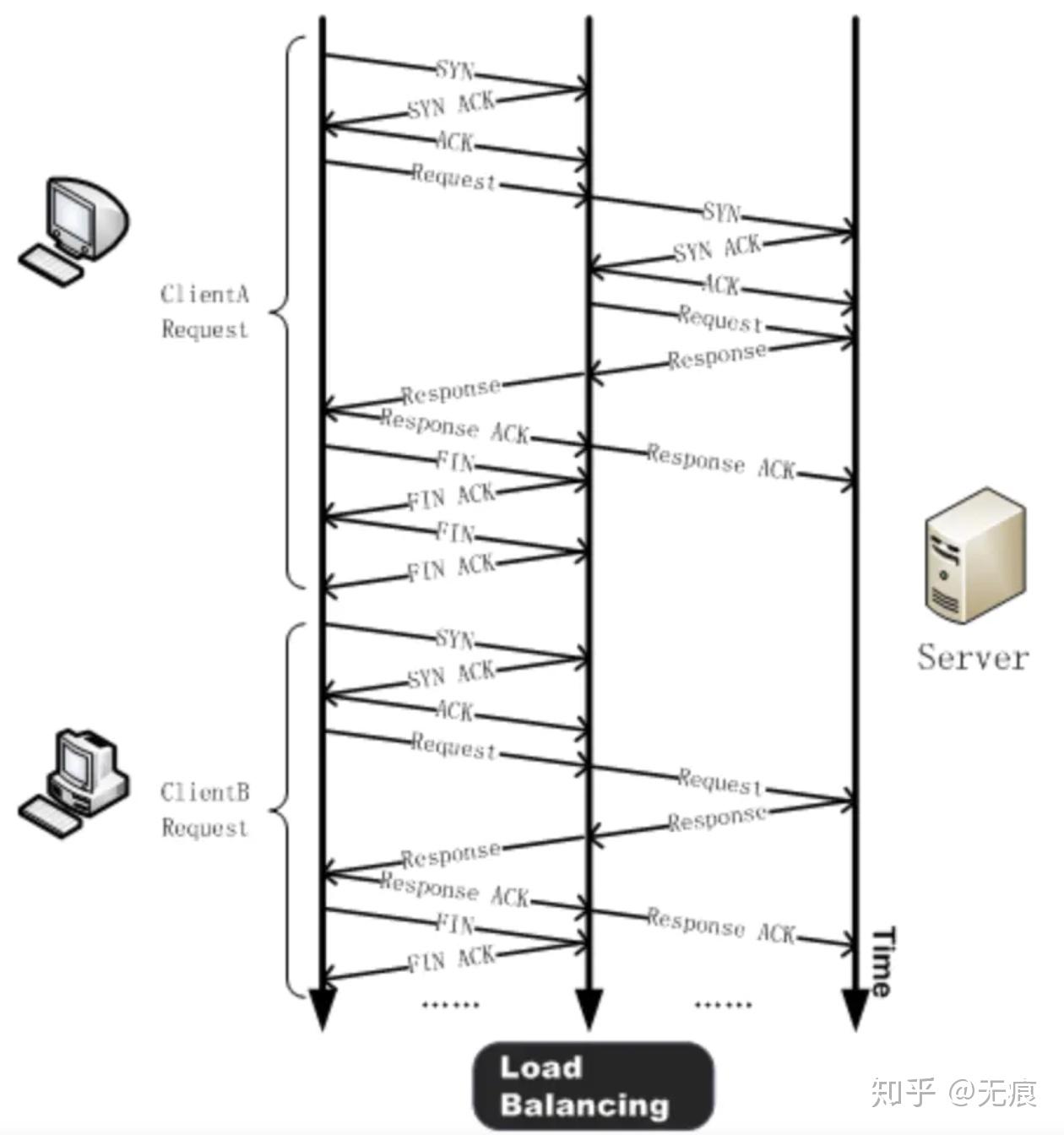
所有TCP连接一开始都要经过三次握手,如下图所示:
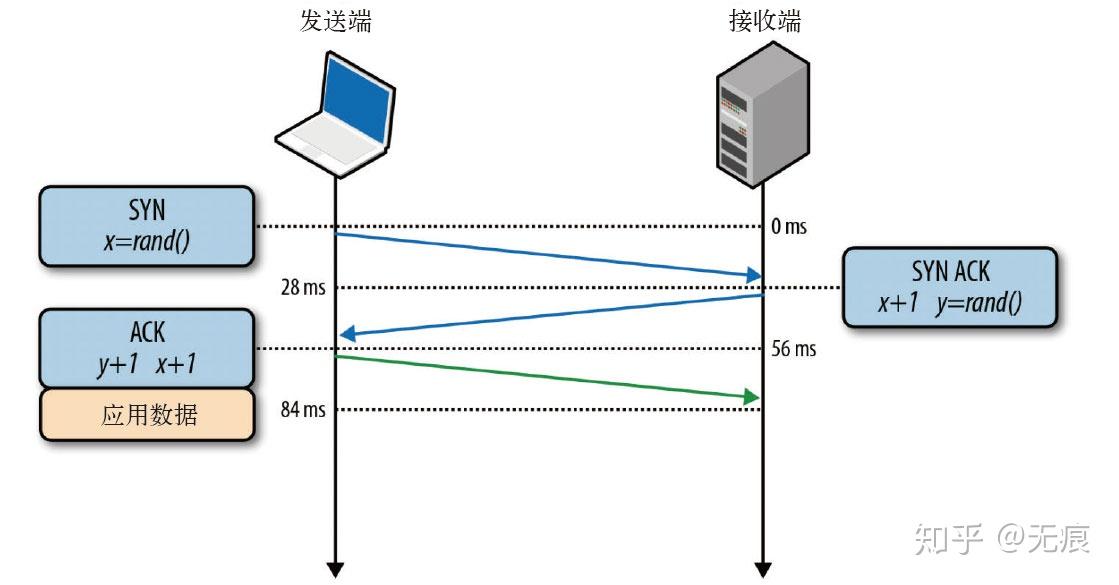
上面的内容我们在书上看过多次,这次我们用wireshark抓包看一下详情:
本机ip为192.168.1.102,服务器ip为122.51.162

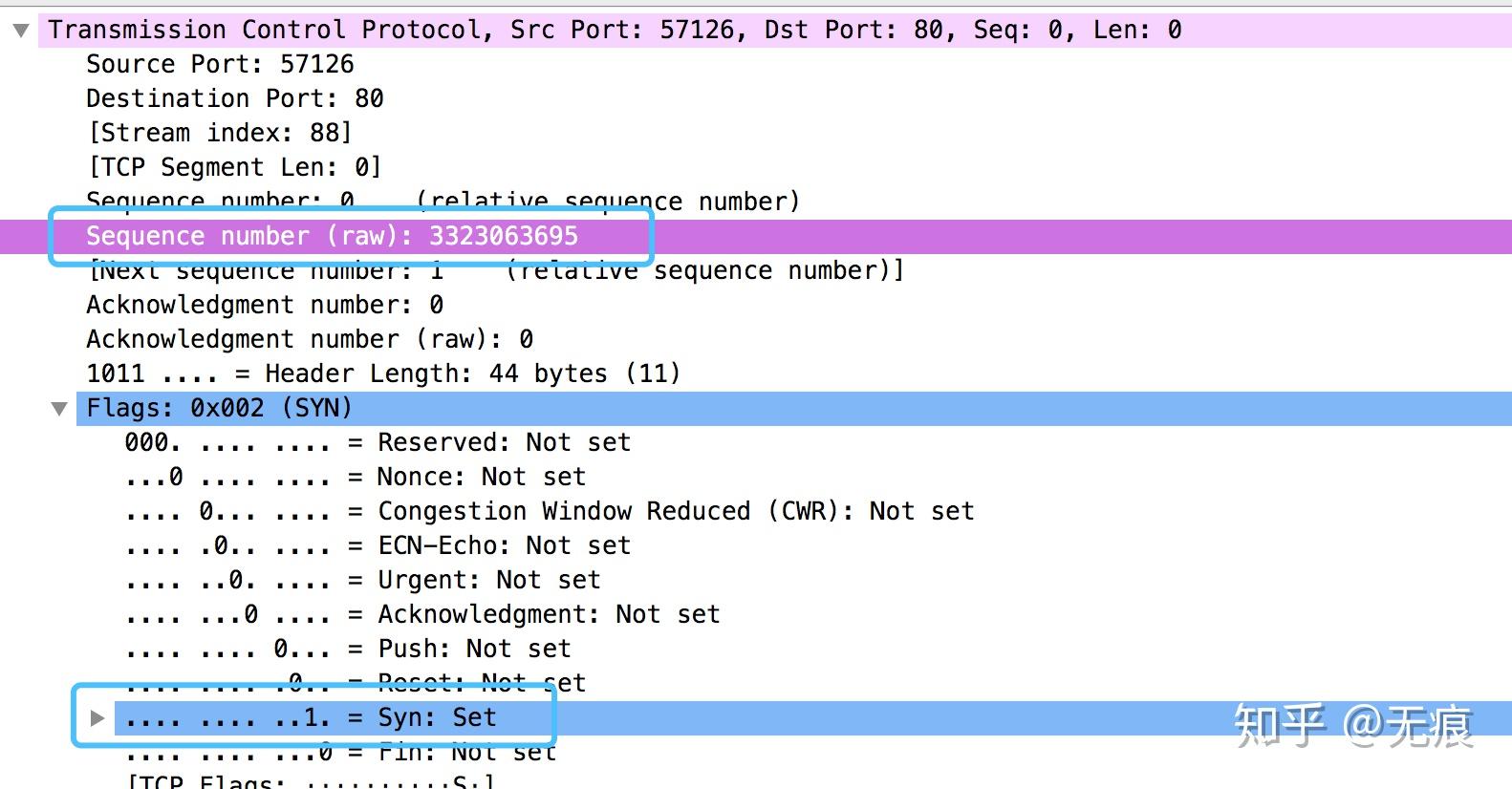
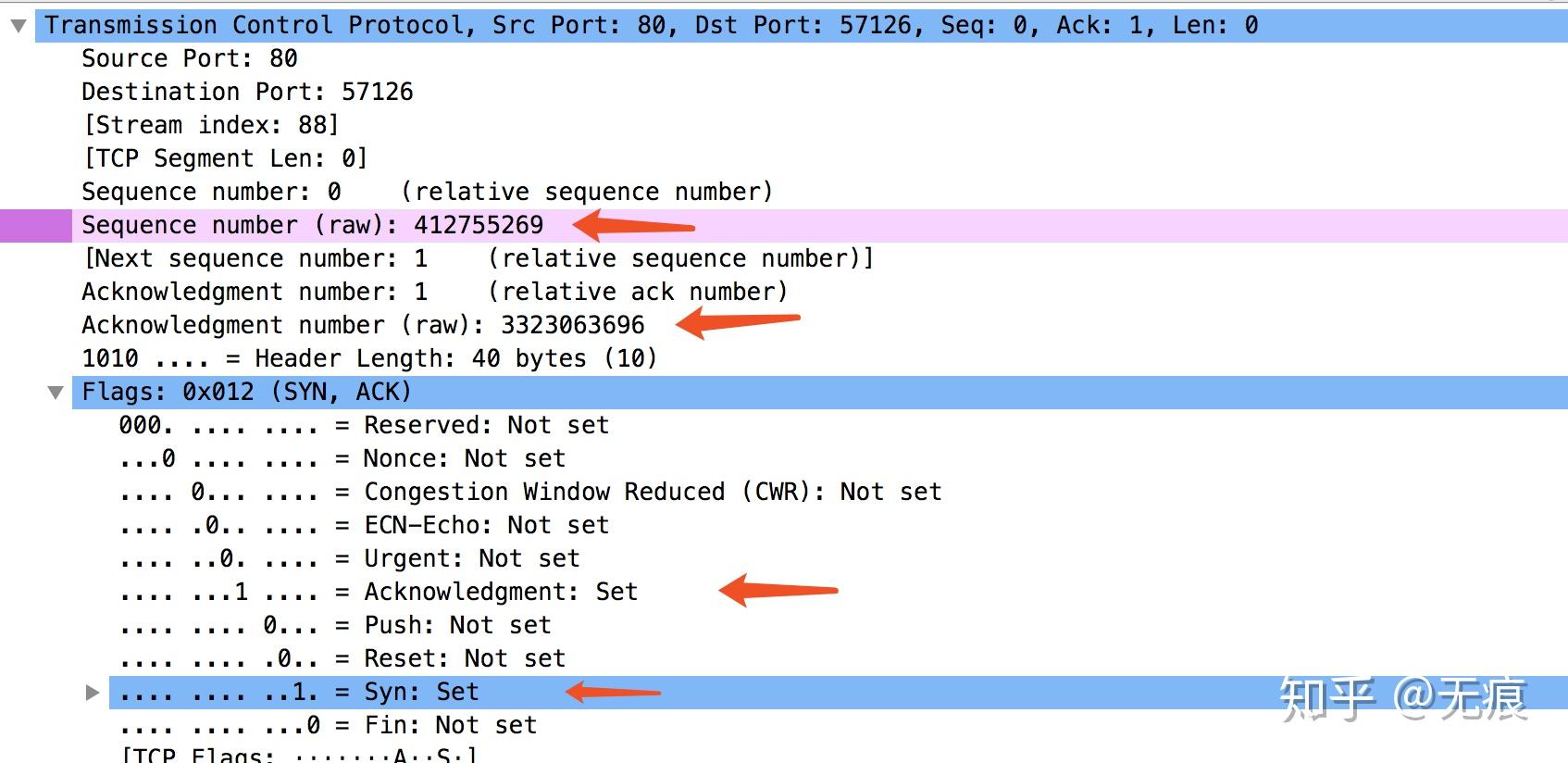
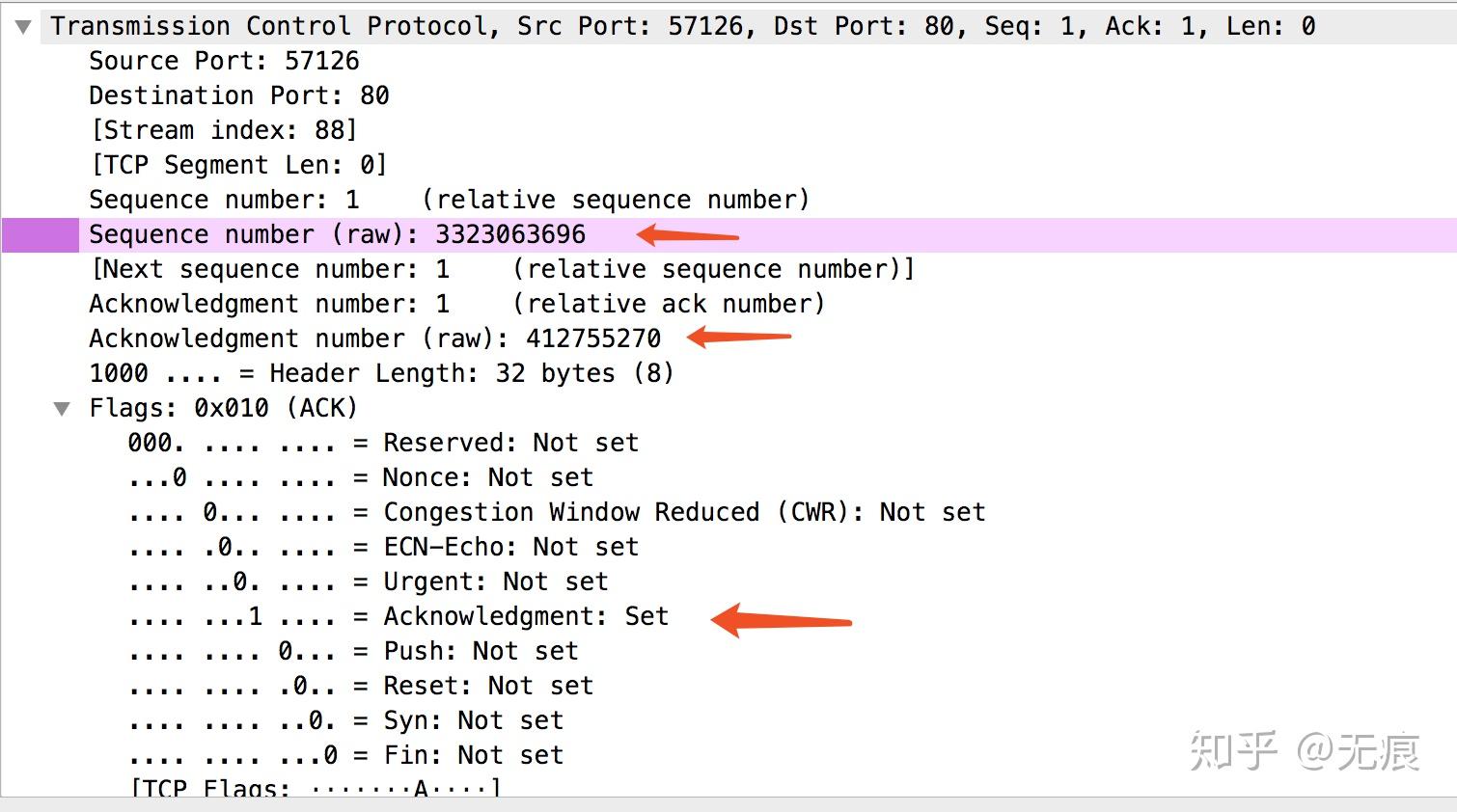
三次握手完成后,客户端与服务器之间就可以通信了。
这个启动通信的过程适用于所有TCP连接,因此对所有使用TCP的应用具有非常大的性能影响,因为每次传输应用数据之前,都必须经历一次完整的往返。
三次握手带来的延迟使得每创建一个新TCP连接都要付出很大代价。而这也决定了提高TCP应用性能的关键,在于想办法重用连接。
TFO(TCP fast open)允许服务器和客户端在连接建立握手阶段交换数据,从而使应用节省了一个RTT的时延。
但是TFO会引起一些问题,因此协议要求TCP实现必须默认禁止TFO。需要在某个服务端口上启用TFO功能的时候需要应用程序显示启用。
查看:sysctl net.ipv4.tcp_fastopen

设置:sysctl -n net.ipv4.tcp_fastopen=0x203
限制:并不能解决所有问题,它虽然有助于减少三次握手的往返时间,但却只能在某些情况下有效,如随同SYN分组一起发送的数据净荷有最大尺寸限制、只能发送某些类型的HTTP请求,以及由于依赖加密cookie,只能应用于重复的连接。
效果:经过流量分析和网络模拟,谷歌研究人员发现TFO平均可以降低HTTP事务网络延迟15%、整个页面加载时间10%以上。在某些延迟很长的情况下,降低幅度甚至可达40%。
Keep-Alive,HTTP 1.1 之后默认开启,指在一个 TCP 连接中可以持续发送多份数据而不会断开连接
Keep-Alive能够实现,需要服务端支持:
Httpd守护进程,如nginx需要设置keepalive_timeout
另外TCP自身也有Keep-Alive,是检测TCP连接状况的保鲜机制
基本原理:客户端(如:ClientA)与负载均衡设备之间进行三次握手并发送 HTTP 请求。负载均衡设备收到请求后,会检测服务器是否存在空闲的长链接,如果不存在,服务器将建立一个新连接。当 HTTP 请求响应完成后,客户端与负载均衡设备协商关闭连接,而负载均衡则保持与服务器之间的这个连接。当有其他客户端(如:ClientB)需要发送 HTTP 请求时,负载均衡设备会直接向服务器之间保持的这个空闲连接发送 HTTP 请求,避免来由于新建 TCP 连接造成的延时和服务器资源耗费。
流量控制是一种预防发送端过多向接收端发送数据的机制。否则,接收端可能因为忙碌、负载重或缓冲区容量有限而无法处理。为实现流量控制,
TCP连接的每一方都要通告自己的接收窗口(rwnd),其中包含能够保存数据的缓冲区空间大小信息。
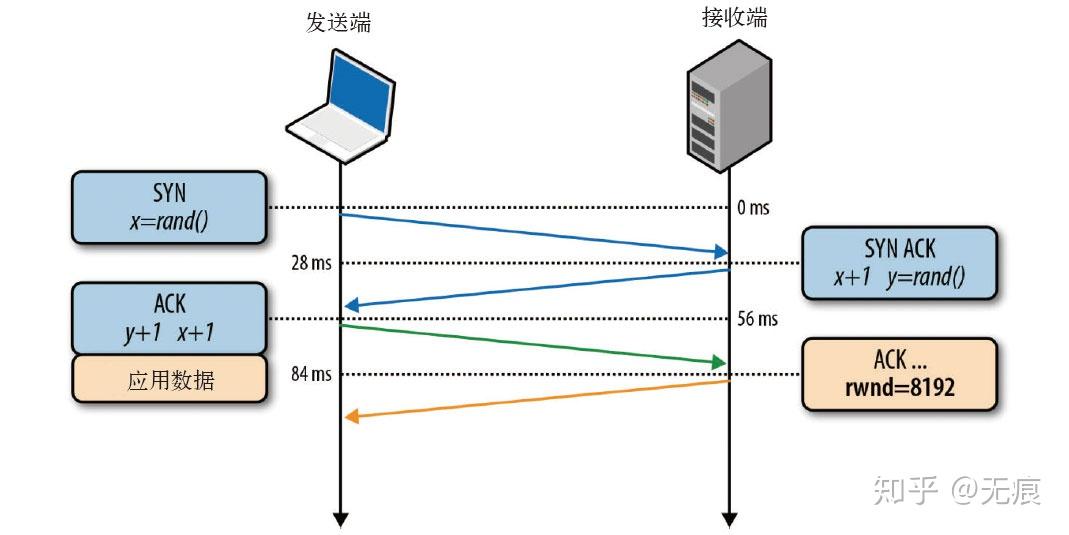
第一次建立连接时,两端都会使用自身系统的默认设置来发送rwnd。每个ACK分组都会携带相应的最新rwnd值,以便两端动态调整数据流速,使之适应发送端和接收端的容量及处理能力。
最初的TCP规范分配给通告窗口大小的字段是16位的,这相当于设定了发送端和接收端窗口的最大值(2的16次方即65 535字节)。为解决这个问题,RFC 1323提供了“TCP窗口缩放”(TCPWindow Scaling)选项,可以把接收窗口大小由65 535字节提高到1G字节!
缩放TCP窗口是在三次握手期间完成的,其中有一个值表示在将来的ACK中左移16位窗口字段的位数。
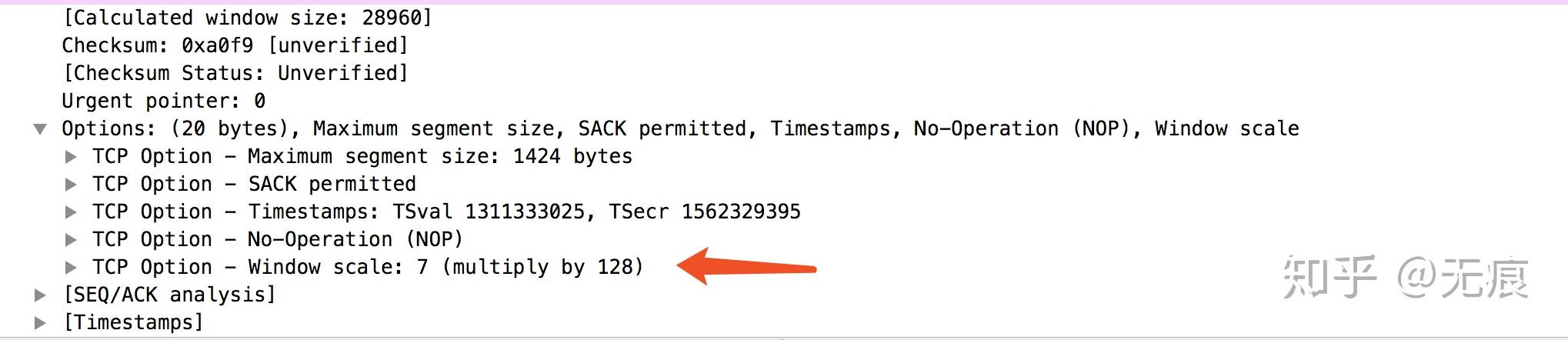
客户端与服务器之间最大可以传输数据量取rwnd和cwnd变量中的最小值。
开启窗口缩放,能使接收窗口大小从2^16升级到2^30,可以获得更好的传输性能。
查看:sysctl net.ipv4.tcp_window_scaling

设置:sysctl -w net.ipv4.tcp_window_scaling=1
效果:比起不开启窗口缩放,能够充分利用带宽
这里讲述一下带宽延迟积。BDP(Bandwidth-delay product,带宽延迟积)数据链路的容量与其端到端延迟的乘积。这个结果就是任意时刻处于在途未确认状态的最大数据量。
发送端或接收端无论谁被迫频繁地停止等待之前分组的ACK,都会造成数据缺口,从而必然限制连接的最大吞吐量。
无论实际或通告的带宽是多大,窗口过小都会限制连接的吞吐量。
知道往返时间和两端的实际带宽也可以计算最优窗口大小。这一次我们假设往返时间为100 ms,发送端的可用带宽为10 Mbps,接收端则为100 Mbps+。还假设两端之间没有网络拥塞,我们的目标就是充分利用客户端的10 Mbps带宽:

窗口至少需要122.1 KB才能充分利用10 Mbps带宽!如果没“窗口缩放,TCP接收窗口最大只有64 KB,无论网络性能有多好,永远无法充分利用带宽。
接收窗口对性能很重要,但拥塞窗口比接收窗口更重要。
客户端与服务器之间最大可以传输(未经ACK确认的)数据量取rwnd和cwnd变量中的最小值,而一开始的cwnd很小,通过慢启动算法不断增大。
慢启动和拥塞避免的算法有很多,这里使用Tahoe版本的TCP版本进行展示,这个也是带有拥塞控制功能的第一个TCP版本,使用的拥塞避免算法为AIMD(Multiplicative Decrease and Additive Increase,倍减加增)。
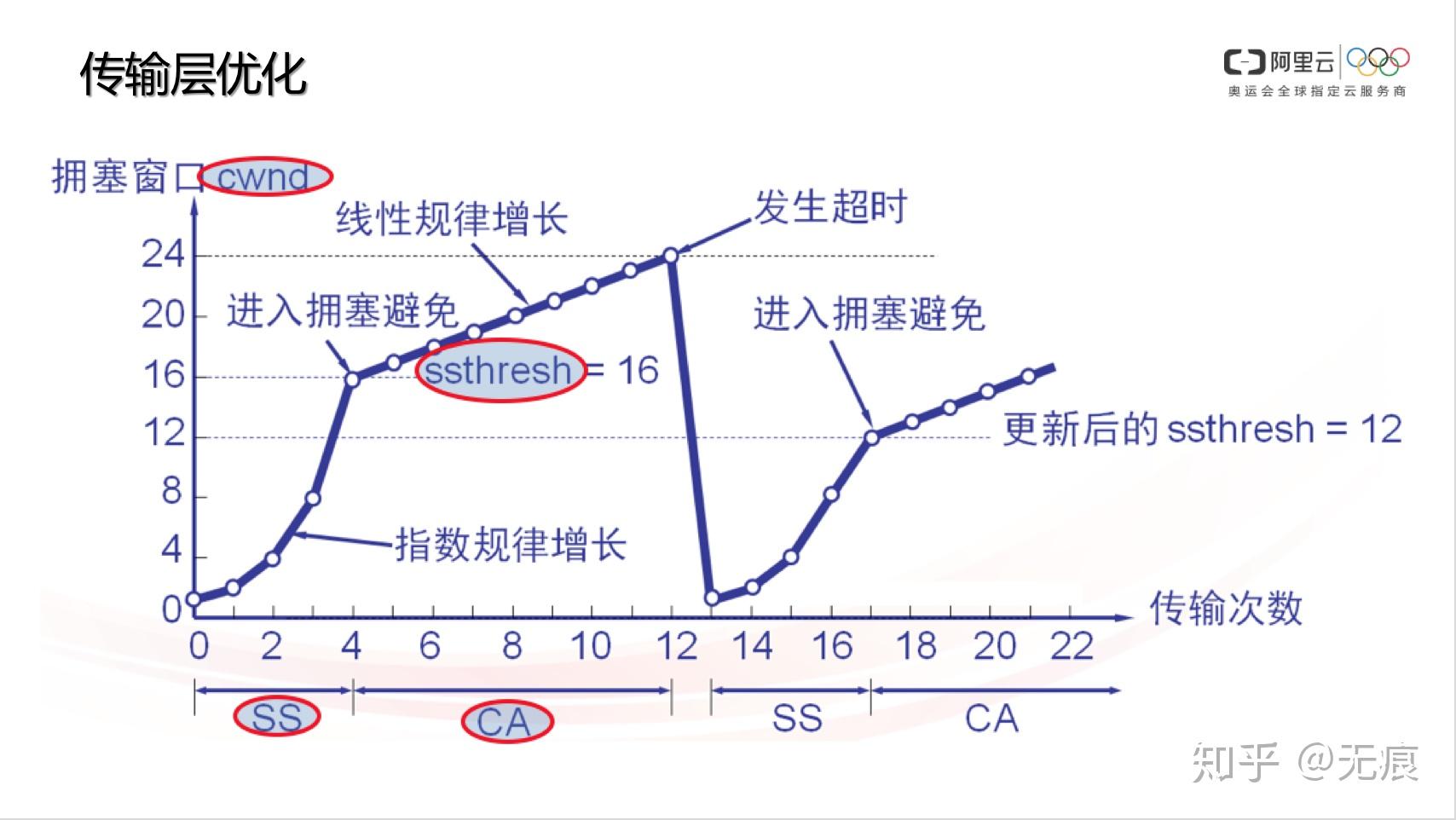
服务器会有一个默认cwnd初始值。最初,cwnd的值只有1个TCP段。1999年4月,RFC 2581将其增加到了4个TCP段。2013年4月,RFC 6928再次将其提高到10个TCP段。
问题:cwnd大小达到N所需的时间
解:
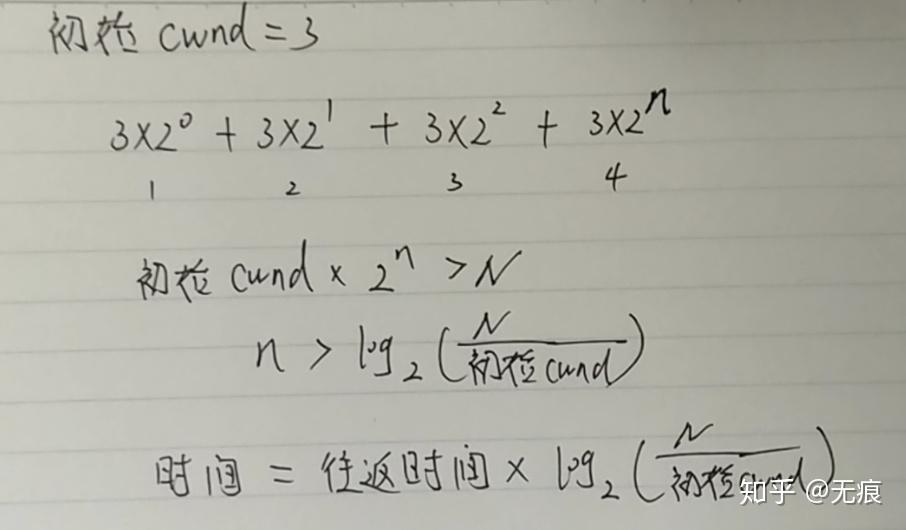
下面我们就来看一个例子,假设:
? 客户端和服务器的接收窗口为65535字节(64 KB);
? 初始的拥塞窗口:4段(RFC 2581);
? 往返时间是56 ms(伦敦到纽约);

这个例子说明网络正常情况下,要达到最大传输量,需要224ms。因为慢启动限制了可用的吞吐量,而这对于小文件传输非常不利,因为拥塞控制尚处于slowstart阶段,传输就完毕了。
查看:
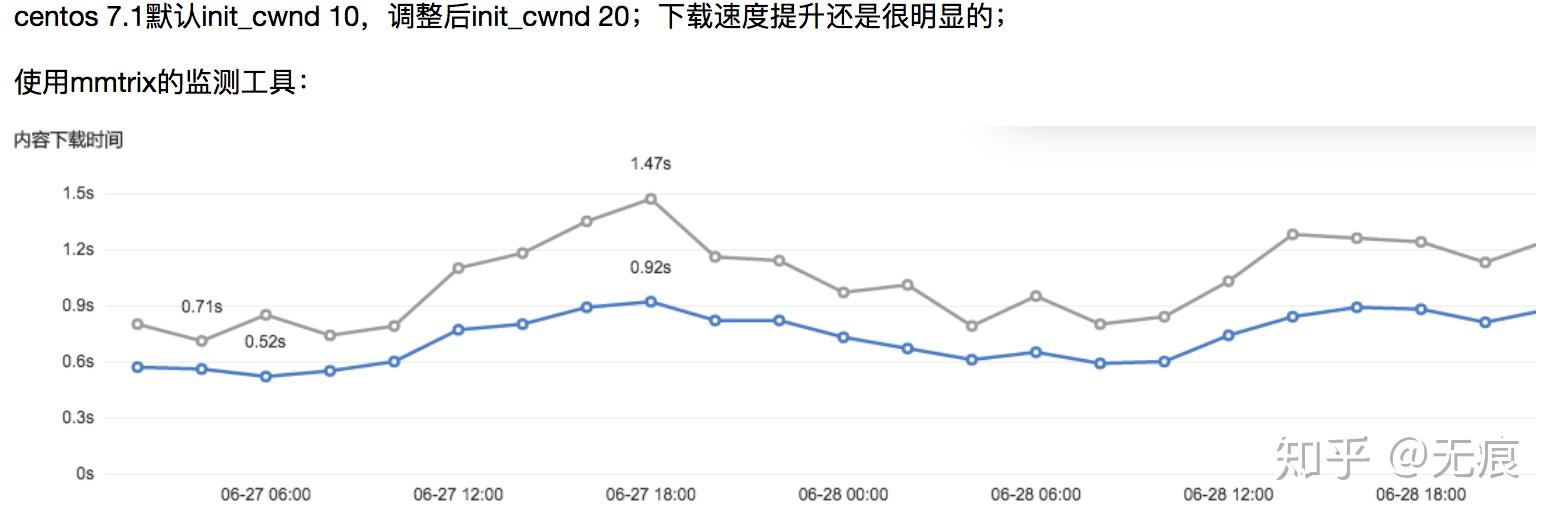
设置:在内核中增加一个控制initcwnd的proc参数,/proc/sys/net/ipv4/tcp_initcwnd。该方法对所有的TCP连接有效。
限制:初始拥塞窗口不能设置特别大,否则会导致交换节点的缓冲区被填满,多出来的分组必须删掉,相应的主机会在网络中制造越来越多的数据报副本,使得整个网络陷入瘫痪。行业内各大cdn厂商都调整过init_cwnd值,普遍取值在10-20之间
效果:
名词解释:SSR(Slow-Start Restart,慢启动重启)会在连接空闲一定时间后重置连接的拥塞窗口。
原因:在连接空闲的同时,网络状况也可能发生了变化,为了避免拥塞,理应将拥塞窗口重置回“安全的”默认值。
查看: sysctl net.ipv4.tcp_slow_start_after_idle

设置: sysctl -w net.ipv4.tcp_slow_start_after_idle=0
效果:对于那些会出现突发空闲的长周期TCP连接(比如HTTP的keep-alive连接)有很大的影响,具体提升性能根据网络性能和数据量大小不同而不同
拥塞控制算法对TCP性能影响很大,除了上面提到的AIMD算法,还有众多其他算法。
PRR(Proportional Rate Reduction,比例降速)就是RFC 6937规定的一个新算法,其目标就是改进丢包后的恢复速度。
效果:根据谷歌的测量,实现新算法后,因丢包造成的平均连接延迟减少了3%~10%。
设置:升级服务器。PRR现在是Linux 3.2+内核默认的拥塞预防算法。
方案:
方案:
队首(HOL,Head of Line)阻塞:如果中途有一个分组没能到达接收端,那么后续分组必须保存在接收端的TCP缓冲区,等待丢失的分组重发并到达接收端。这一切都发生在TCP层,应用程序对TCP重发和缓冲区中排队的分组一无所知,必须等待分组全部到达才能访问数据。在此之前,应用程序只能在通过套接字读数据时感觉到延迟交付。

优点:应用程序不用关心分组重排和重组,从而让代码保持简洁。
缺点:分组到达时间会存在无法预知的延迟变化。这个时间变化通常被称为抖动,也是影响应用程序性能的一个主要因素。
无法优化,这是TCP的基础逻辑,目前没有优化的可能。
无需按序交付数据或能够处理分组丢失的应用程序,以及对延迟或抖动要求很高的应用程序,最好选择UDP等协议。
一般的音频或者游戏等应用,可以选择使用UDP协议
大家如果喜欢我的文章,可以关注我的公众号(程序员麻辣烫)
往期文章回顾:
技术
读书笔记
思考





