




学习优化狭义的定义:采用机器学习或者深度学习的方法来学习优化算法。
学习优化广义的定义:采用机器学习或者深度学习来提升基于优化的决策过程。
狭义的定义主要还是侧重在于机器学习或者深度学习的方法来帮助单一的优化算法,而广义的定义里边 决策过程包含的概念比优化算法更加广泛,像建模和预测都属于决策过程。
** 为了后文描述方便我们把 学习优化,Learning to Optimize 也简写作 L2O **
从上面的定义可以看到,L2O 涉及两个主要部分:1机器学习;2是传统优化。在具体说明学习优化之前我们需要对机器学习和优化分别来做一个介绍:

机器学习主要是使用历史数据使计算机能够从数据中学习模式、理解规律,并做出决策或预测。
优化旨在寻找最佳解决方案或最优决策,以优化特定问题的效果。这一领域通常涉及到在有限资源下,通过最有效地利用这些资源,使得特定目标函数的值最大化或最小化。
传统优化主要是由两个重要的部分构成:1个是建模(New Optimizees)把实际中的问题转化为数学模型来描述;另外一个是设计优化算法或者选择优化算法(Selected Optimizer)
那么L2O就和传统优化不一样的地方在于 L2O 会先通过历史上的一些训练算例(Trainning Optimizees)来训练出一个 学习优化器(Learable Optimizer), 这个过程其实就是我们在训练神经网络。训练完毕之后真正在线使用的时候 直接拿这个 Learable Optimizer 就可以得到优化问题的最优解了。整个过程如下图所示:
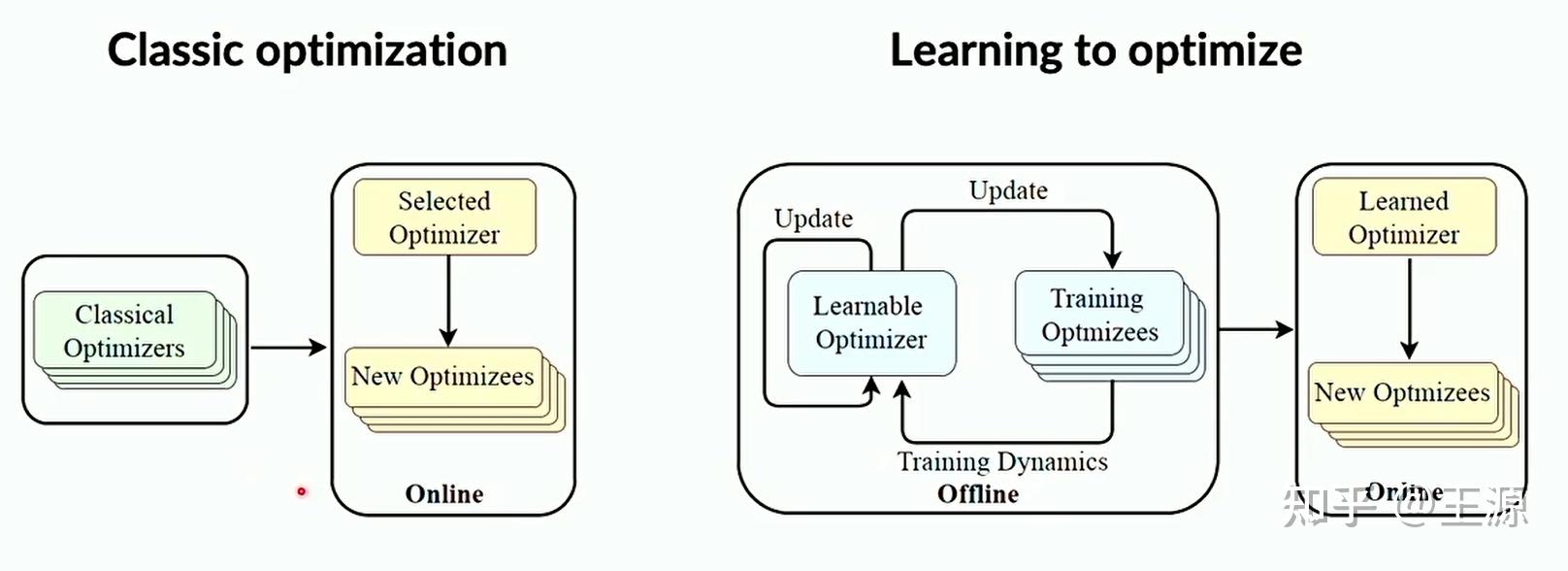
那么L2O相对于传统优化的优势是什么?主要有以下两方面:
Hand-free modeling 的优点 是减少了人为手动的干预和设置,因为机器学习可以自动地提取特定优化问题的特性,也可以从历史上数据中学习到很多优质的解的信息,这就减少了人为建模和算法参数设计的过程。
Faster convergence 的优点是L2O的计算速度非常快。传统优化算法求解大规模优化问题一般来说是非常耗时的,而L2O在线使用的时候就是给一个输入到神经网络,然后神经网络返回一个输出,这个的计算量是很低的(当然训练这个神经网络的计算量还是很大的,这里我们只谈在线的使用)。
总体来说,hand-free modeling 主要是针对建模和算法参数设计的,而 Faster convergence 主要针对是求解速度的。
随着以深度学习为代表的机器学习算法的能力的大幅度提升,L2O也被随之带火了起来,在L2O这个领域正式诞生之前事实上已经有很多工作就是在做L2O相关的事情,我们这里来做一个回顾可以更好的对这个领域有一个全面的认识。总得来说早期的工作主要有三个方面:
深度学习的训练本身就是一个优化问题,那么这个优化问题里边含有很多超参数,例如学习率,正则化系数,batch size 等等,那么这些超参数是可以采用L2O的思想来寻找的。
那么另外一个比较关键的L2O的早期工作就是 选择算法,这些工作都是可以自动的探测出问题的结构进而根据问题的结构选择是否启动算法中某些策略,或者具体启动哪一类的策略。这类方法已经在很多求解器中被使用了,例如可以决定是否启动启发式算法,是否启动某一种割平面算法,是用动态规划来求解还是用 branch and bound 算法来求解等等。
强化学习这个又是另外一套思路。强化学习本身是针对序列决策问题的,但是里边大概率也要依靠机器学习或者深度学习的方法来学习 value function 或者 policy,一些不便于用监督学习直接完成的任务,有可能会考虑强化学习。
早期有两篇非常经典的 L2O 的 paper 非常值得一读:
这两个 paper 有一个相同的 work flow 如下所示:
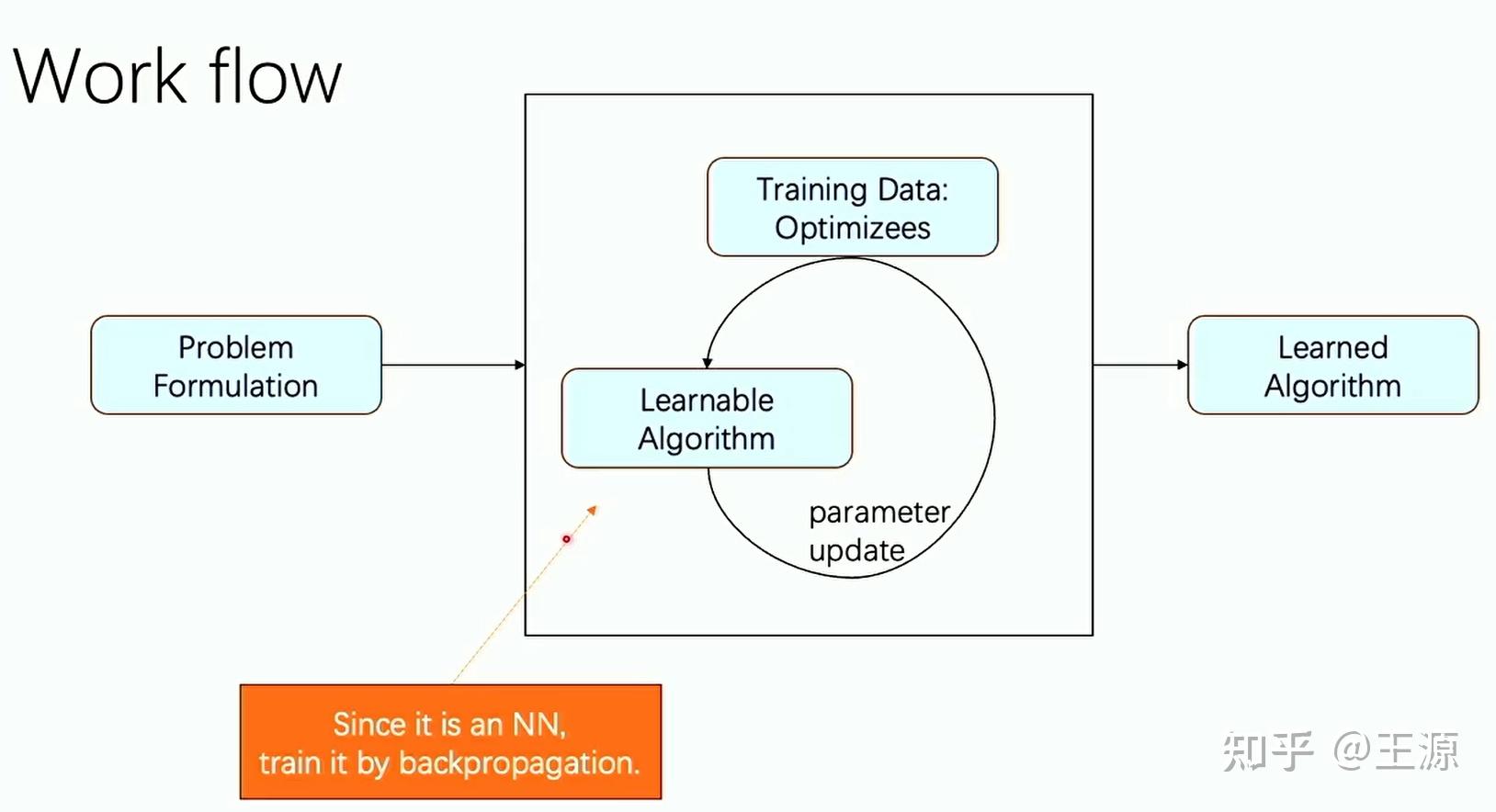
这两篇 paper 其实从今天的观点来看是比较简单和直观的。这两个paper 的创新点在于他们发现了很多连续优化搜索的过程本身就是一个搜索过程,这个过程本质上是很像神经网络学习的,例如 RNN 这样的神经网络。那么自然而然一个idea就产生了,我想把这个搜索优化过程用神经网络来近似。整个流程如上图中所示。
在今天这两篇paper的工作已经被淘汰了,但这两篇paper是一个非常好的开始,它奠定了一个很好的框架。我们可以看到这类交叉研究事后去看其实都不难,但是能同时精通机器学习和传统优化的人是比较少,这就决定了这个方向是一个非常需要交叉型人才的方向。
1 泛化性:我要解的优化问题本身结构是不变的,只是这个优化问题的数据会发生变化,或者说数据的分布慢慢也会发生变化。那么我L2O训练出的模型是否可以能有泛化性的保证。
2 稳定性:传统的神经网络主要是解决预测的问题,例如图像识别的问题,而在L2O里边我们是用神经网络来求解优化问题,优化问题的难度要远远难于图像识别的问题。我训练神经网络是一个迭代算法,那么这个迭代算法什么时候收敛,我多迭代几步是不是会发散掉,我们观察到在L2O里边这个稳定性的问题会变得非常致命。这一点在传统的图像识别问题里就没有。
3 训练时间:训练的过程时间可能会比较长。在连续优化问题中训练时间还可以接受,然而在离散优化问题中L2O的训练时候会大大增加。
离散优化问题有很多种称呼,主要的有这三大类:
组合优化和约束规划都可以等价转化为一个混合整数规划问题。在很多场合之下,我们也经常混用这三个概念,因此这三个概念互相之间的边界目前来说是越来越模糊了。
在实际的应用问题中,离散优化问题可以说占有举足轻重的地位,大多数的实际问题都是离散优化问题。NEOS曾经统计过 混合整数线性规划问题占总的优化问题的79%,混合整数线性规划还只是离散优化问题的一个子集,足以说明离散优化问题对实际的重要性。
离散优化 L2O常见的三个套路:
离散优化的 L2O的挑战如下所示:

第一个很自然很好理解就是 离散优化是不可微分的一个问题,当然这个问题可以通过引入 softmax 或者采用强化学习里边 PPO 算法的思想来解决。
第二个就是神经网络比较适合的问题是那种有局部特性的问题,例如像图像识别的问题就是局部的问题,但是在优化问题里边往往是牵一发而动全身的问题,例如统计一个数字序列中有多少个1的问题,这个问题用一个搜索算法可以非常容易的去实现,但是神经网络想学习到这个问题就比较困难就是因为这个是一个全局的问题,必须要看完整个序列才能知道有多少个1,另外就是本身序列的长度是变化的而不是固定的,最后就是这个优化问题最终往往都是线性不可分的。

第三个就是离散优化问题背后的本质是有很大的不同的,例如 TSP问题是决定城市访问的序列,SAT是满足一个逻辑表达式,而背包问题是从一堆物体中选出一个满足 capacity 的子集。可以看到这三个经典问题都是离散优化中非常常见的问题,但是他们的表达形式各异,背后的原理大相径庭。
【1】印卧涛等 重庆国家数学中心 学习优化(Learning to Optimize)系列课程 (本文大部分内容均来自于本课程)
【2】Chen T, Chen X, Chen W, et al. Learning to optimize: A primer and a benchmark[J]. Journal of Machine Learning Research, 2022, 23(189): 1-59.





